Towards Robust Neural Retrieval Models with Synthetic Pre-Training
引言
传统的稀疏检索模型,如BM25和TF-IDF依赖于简单的字词匹配,而深度检索模型,如DPR,将查询句和文档分别编码为连续向量表示,然后计算其向量表示之间的相似性。
诚然,深度检索模型取得了巨大的成功,但是他们都是遵循着标准的有监督学习的方式——训练样本和测试样本是从相似的分布中采样得到的。
于是作者提出了自己的疑问——这样标准的有监督学习的方式是否可以泛化到更加实用的零样本的场景呢?
从机器阅读理解任务中的合成训练方式收到启发,作者进一步想尝试这样的方法对于信息检索的场景是否也是有用的,包括零样本的场景。于是作者构造了合成的训练数据,具体的方式由下文介绍。
方法
令 $c$ 是文档集合,$d \in c$ 是一个文档,一个检索的样本包括了一个问题 $q$ 和一个段落 $p \in d$,$p$ 中包含了对于 $q$ 的回答 $a$ 。记 $s$ 是 $p$ 中包含答案 $a$ 的一个句子。
作者训练了一个样本生成器。它首先从输入$p$ 中选择一个候选句子 $s$,然后从 $s$ 中选择一个候选答案 $a$ ,最后生成一个对应的问题 $q$。为了达到这个目标,作者微调了BART,它从 $p$ 中生成一个有序三元组 $(s,a,q)$ 。训练使用的标记四元组 $(p,s,a,q)$ 是从NQ数据集中得到的。
对于每个生成的问题 $q$,作者使用BM25算法为其选择了一个不含答案的段落作为负样本。在合成的数据上完成训练后,作者依旧在IR的样本上进行了微调,作者将自己的方法命名为AugDPR。
实验
数据集
作者在NQ数据集上构造合成样本,然后在TriviaQA、WebQuestions、WikiMovies和BioASQ等数据集上进行检索,其中BioASQ是生物医药领域的检索对话数据集。
Baseline
作者使用了BM25和DPR分别作为稀疏检索和深度检索的baseline。评价指标是top-k的准确率。
结果
下图展示了各baseline方法和作者提出的AugDPR在NQ数据集上的检索效果。

可以看出,合成的训练方式相比于baseline方法有着巨大的提升。
为了探究AugDPR跨领域的泛化能力,作者测试了AugDPR在相邻领域和不相邻领域的检索能力。如下图所示。
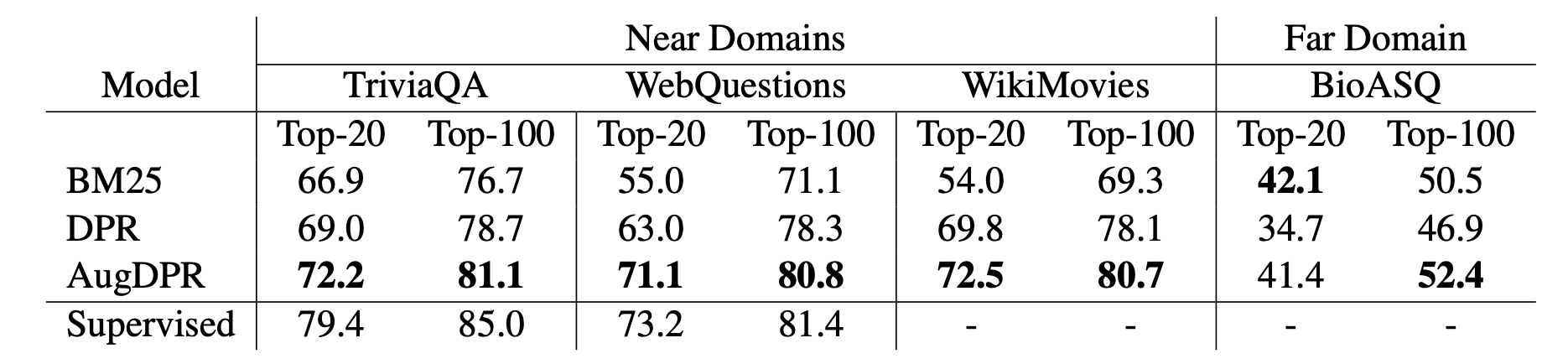
为了对比,作者同时加入了DPR在TriviaQA和WebQuestions两个数据集上进行有监督学习的结果。
可以看出,在相似领域的检索中
- DPR和AugDPR都超越了BM25,同时作者提出的AugDPR在所有的数据集上都超越了DPR
- 在WebQuestions数据集上,AugDPR甚至接近了有监督学习的方法
在不相似领域的检索中,可以看出
- BM25是比较强的baseline,比DPR的效果要好
- 作者提出的AugDPR减小了BM25和DPR之间的差距