DYPLOC - Dynamic Planning of Content Using Mixed Language Models for Text Generation
来自ACL21,代码已开源 Github地址
Motivation
研究的问题:观点长文本生成
目前面临的挑战:
- 现有的神经网络生成方法缺乏一致性,因此需要使用content planning的方法
- 需要多种类型的信息来指导生成器生成主观和客观的内容
因此,作者提出使用动态的content planning来解决观点长文本生成的问题。
方法
任务描述
观点文本生成任务的输入是一系列内容项,每个内容项包括一个标题 $\boldsymbol{t}$ 、一系列实体 $E_i$,例如 {United States, 9/11 attacks} 和一系列核心概念 $C_i$,例如{attack, knowledge}。作者提出的DYPLOC模型,首先通过预测额外的相关概念 $C_{i}^{+}$ 来扩展 $C_i$,然后生成相关论点 $\boldsymbol{m}_i$。增强后的内容项将被并行编码,在解码阶段,会有一个评分网络对所有的内容项进行打分,然后选择相关的内容。最后输出由多个句子组成的观点文本。
流程图如下所示:
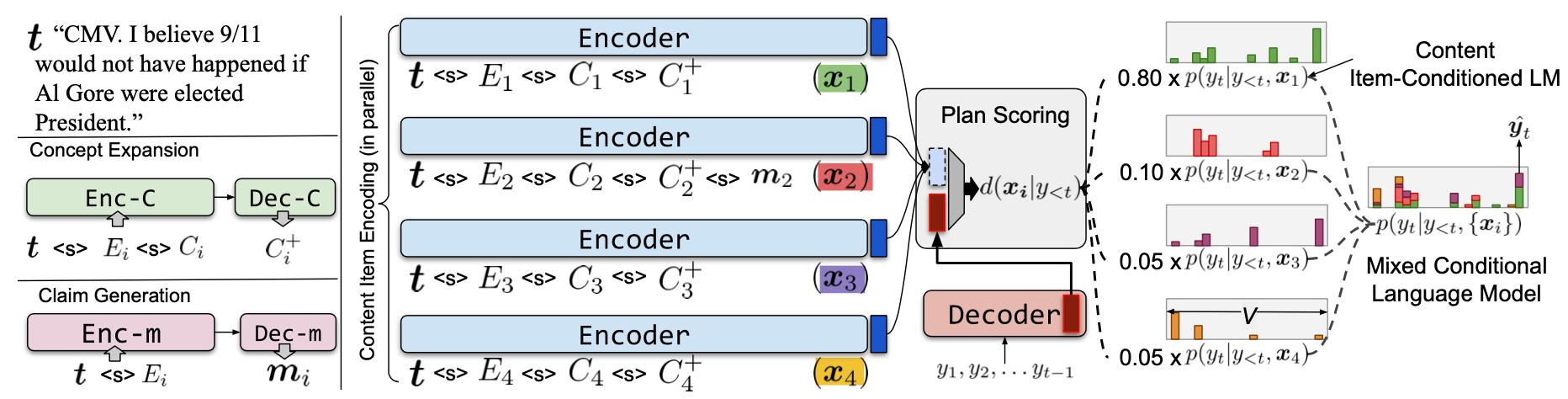
内容项增强
内容项增强包括两部分,分别是概念扩展(Concept Expansion)和论点生成(Claim Generation)。
- 概念扩展
概念扩展的目的是,从抽象的核心概念中,预测与给定话题更加相关的具体的概念。例如,对于核心概念{make, happen}和实体{Bill Clinton, 9/11 attacks},可以生成更加具体的概念{mistake, administration}。
具体做法是,使用微调的BART模型,基于原来的内容项 $C_i$ 来逐词生成 $C_{i}^{+}$。
\[C_{i}^{+}=BART\left(\boldsymbol{t}, E_{i}, C_{i}\right)\]- 论点生成
作者认为,想要生成一致性的观点文本,需要控制论点主题,而这个没法通过离散的概念来表示。因此,使用自然语言文本更适合传达核心的论点。
作者的做法是利用另一个微调的BART模型,以标题 $\boldsymbol{t}$ 和实体 $E_i$ 为输入,输出论点文本。
内容实现
在获得了增强的内容项之后,作者使用了BART将每个内容项 $\boldsymbol{x}_{i}$ 分别编码为 $\boldsymbol{h}_{i}$。编码前,先将每个内容项里的标题、实体、概念和论点等拼接在一起,然后插入<s>作为区分。作者设计了一个评分网络 $d\left(\boldsymbol{x}_{i} \mid y_{<t}\right)$ ,根据已经生成的词,来对不同的内容项进行选择和排序。
在每一个生成阶段 $t$,输出词的概率通过所有内容项的条件概率加权计算得到:
\[\begin{array}{l} p\left(y_{t} \mid y_{<t}\right)=\sum_{i} d\left(\boldsymbol{x}_{i} \mid y_{<t}\right) p\left(y_{t} \mid y_{<t}, \boldsymbol{x}_{i}\right) \\ d\left(\boldsymbol{x}_{i} \mid y_{<t}\right)=\operatorname{softmax}_{i}\left(e_{i t}\right) \end{array}\]其中 $p\left(y_{t} \mid y_{<t}, \boldsymbol{x}_{i}\right)$ 对应着以 $\boldsymbol{x}_{i}$ 为输入的语言模型。而 $d\left(\boldsymbol{x}_{i} \mid y_{<t}\right)$ 决定了 $\boldsymbol{x}_{i}$ 的重要性,它起到了content planning的作用。$e_{i t}$ 通过两层的前馈网络计算得到:
\[e_{i t}=\boldsymbol{W}_{o} \tanh \left(\boldsymbol{W}_{d}\left[\boldsymbol{h}_{i} ; \boldsymbol{s}_{t}\right]\right)\]$\boldsymbol{h}_{i}$ 是内容项 $\boldsymbol{x}_{i}$ 的表示,$\boldsymbol{s}_{t}$ 是解码状态。
损失函数
DYPLOC模型的训练是端到端完成的。损失函数分为两部分,分别是标准的生成过程中的交叉熵损失 $\mathcal{L}_{g e n}$ 和学习 $d\left(\boldsymbol{x}_{i} \mid y_{<t}\right)$ 的损失函数 $\mathcal{L}_{\text {plan }}$:
\[\mathcal{L}(\theta)=\mathcal{L}_{g e n}(\theta)+\mathcal{L}_{\text {plan }}(\theta)\]在解码时,每个语言模型 $p\left(y_{t} \mid y_{<t}, \boldsymbol{x}_{i}\right)$ 和预测的评分 $d\left(\boldsymbol{x}_{i} \mid y_{<t}\right)$ 是并行计算的,然后基于混合的语言模型逐个生成每个词。
实验
任务和数据集
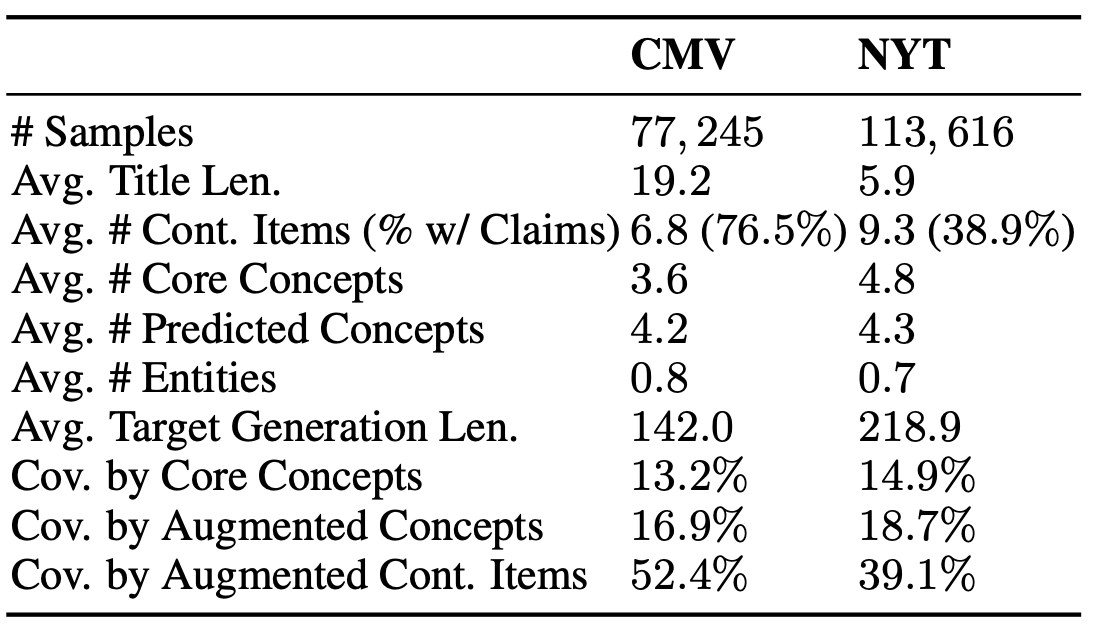
作者尝试了两个任务——辩论文本生成和观点文本撰写。两个任务分别使用了CMV数据集和NYT数据集。有关两个数据集的统计如下所示。
Baselines
作者使用了四个baseline模型,分别是:
- RETRIEVAL:先计算每个内容项的TF-IDF权重加权查询,用于在训练集中查询最相似的句子,然后使用训练的指针网络进行排序。
- SENTPLANNER:基于LSTM的seq2seq模型,拥有一个独立的text planning解码器,先根据注意力机制选择关键短语,然后再用作生成。
- SEQ2SEQ:微调的BART模型,输入是原始的内容项,没有使用预测得到的概念词和论点句。
- SEQ2SEQFULL:同上,但是使用了与DYPLOC模型一样的增强的内容项作为输入。区别是只是将内容项拼接起来作为输入。
自动评价结果
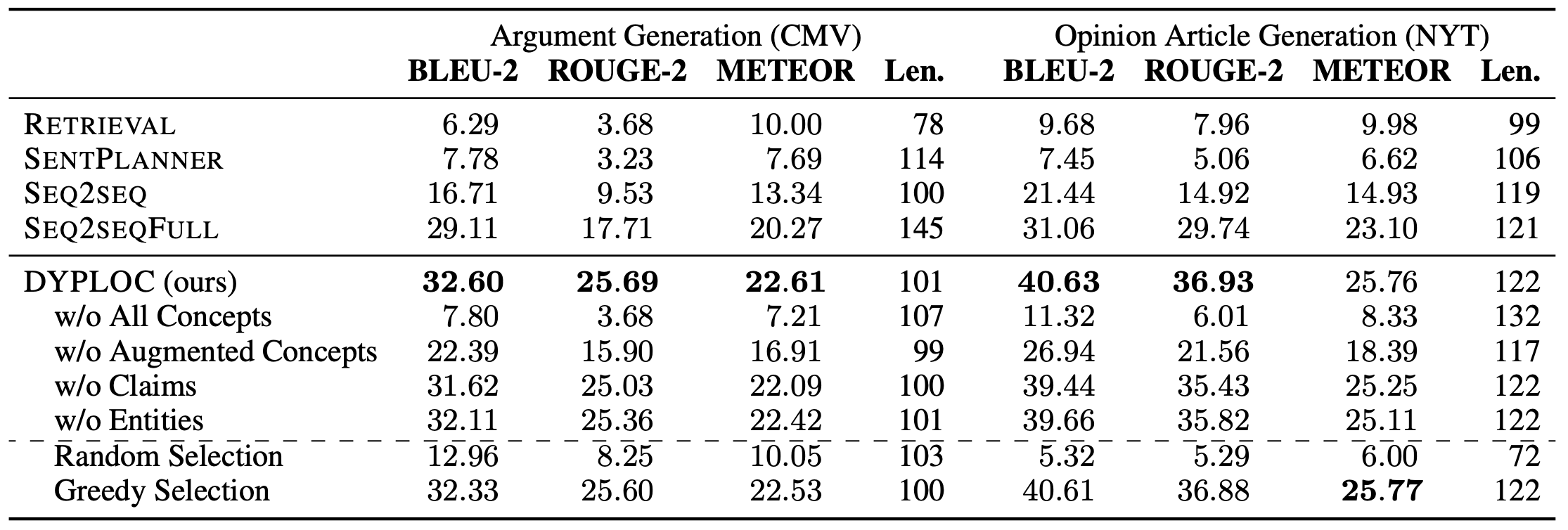
作者首先将自己提出的DYPLOC模型与四个baseline模型进行比较,最终结果如下
可以看出——
- DYPLOC在两个数据集上的所有指标上都超越了四个baseline,特别是领先了与DYPLOC使用了相同数据的SEQ2SEQFULL,这证明了作者所提出的方法的优越性。
- SEQ2SEQFULL与SEQ2SEQ的表现有较大的差距,这表明增强内容项是非常必要的。
- 没有使用预训练模型的方法与使用BART的方法有较大的差距,这充分证实了预训练的重要性。
同时为了验证内容项中各个部分的作用,作者进行了消融实验,通过逐个移除概念、论点或者实体,对比模型的表现,可以看出,在只使用部分的内容项时,模型的表现有所下降,特别是核心概念。而论点句和实体对产生有信息量的文本帮助不大。
另外,为了测试评分网络的加权选择的重要性,作者尝试使用随机选择或者贪心选择(选择最大的那一项)代替评分网络中的加权方式。结果表明,使用随机选择的方式会严重损害模型的一致性和连贯性;另一方面,使用贪心选择的方式则对最终的结果影响不大。作者也证实了,在实验中发现,评分网络会将某个内容项打出很高的分,因此在这样的条件下,加权选择和贪心区别不大。