原文地址:https://aclanthology.org/2021.acl-long.371/
代码地址:https://github.com/zwkatgithub/DSCAU
摘要
这篇文章使用因果干预(Causal Intervention)的方法来去除命名实体识别(NER)任务中的字典偏差的问题。作者通过SCM解释了字典偏差中的两部分偏差的来源,然后分别通过后门调整和因果无关正则化解决了两个偏差。最后的实验证明了作者提出的方法的有效性和鲁棒性。
引言
首先先介绍一下命名实体识别这个任务
命名实体识别(英语:Named Entity Recognition),简称NER,是指识别文本中具有特定意义的实体,主要包括人名、地名、机构名、专有名词等,以及时间、数量、货币、比例数值等文字。
NER是许多NLP任务(如关系抽取、问答系统)的基础。有监督的NER方法通常依赖于高质量的标注数据,而这有很高的标注代价,因此限制了有监督的NER方法的应用。远程监督的NER方法(DS-NER)可以根据易得的字典自动地从纯文本中匹配实体以生成训练数据,大幅地减少了标注成本,因此被广泛应用。
然而,DS-NER模型存在着字典偏差,因此严重地影响NER模型的泛化能力和鲁棒性。具体来说,NER使用的字典通常是:(1)不完整的,缺少实体(2)有噪声的,包含错误的实体(3)模棱两可的,一个名称可以被理解为多种类型的实体。而且模型只会标注为字典中标记为正样本的实体,而忽略其他的实体,这样的带有偏差的字典不可避免地会让训练出来的NER模型对字典内的名称过拟合,同时对字典外的名称欠拟合。这样的现象称为字典内部偏差(intra-dictionary bias)。
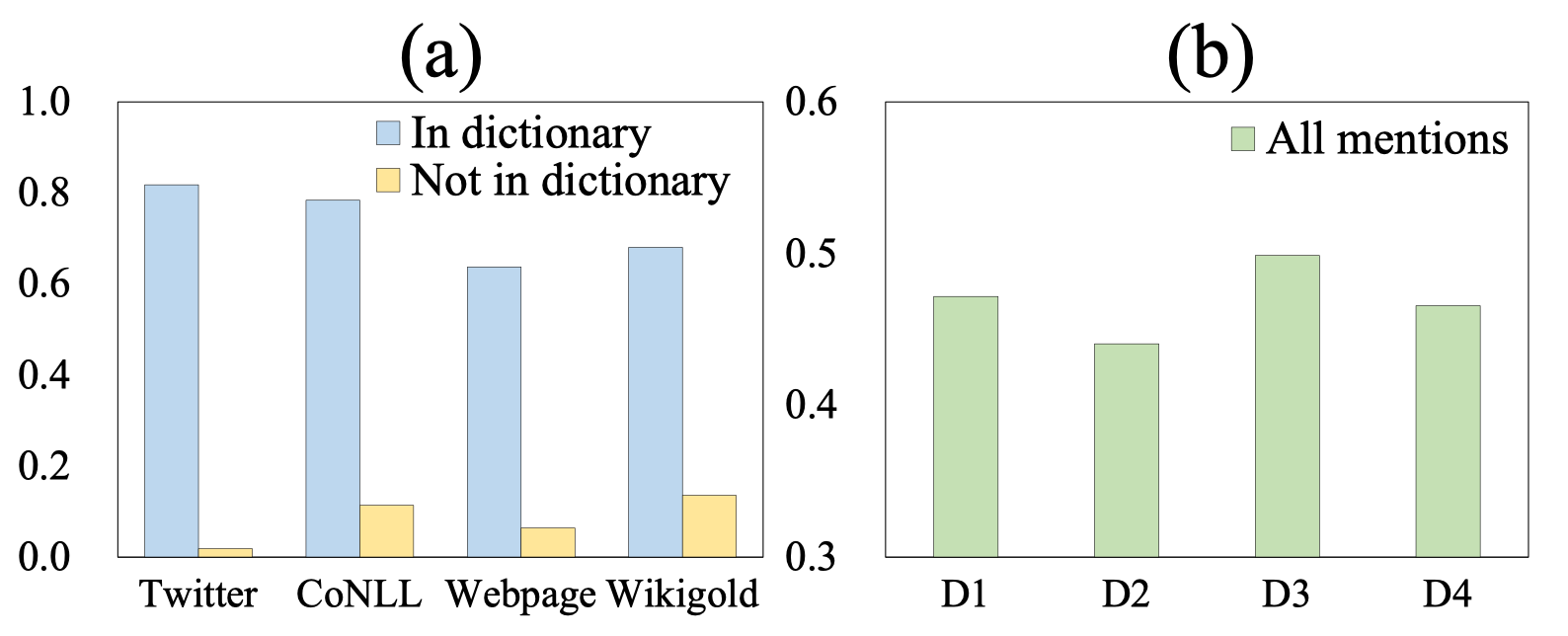
上图展示了DS-NER模型(RoBERTa+Classifier)预测的概率。由图(a)可以看出,字典内外的预测概率相差特别大,字典外的平均预测概率小于0.2,这意味着大部分字典外的词都无法被召回。这种巨大的偏差导致模型对微小的扰动十分敏感,论文的作者称之为字典间偏差(inter-dictionary bias)。图(b)表示在从原字典采样的四个子字典(每个都包含了原字典90%的实体)后,在同一个模型上训练的结果,可以看到不同采样下的预测概率也是不同的,即使这些字典的大部分实体都是共享的。因此,字典偏差的学习会对NER模型的性能和鲁棒性有非常严重的影响。
DS-NER因果图和字典偏差的来源
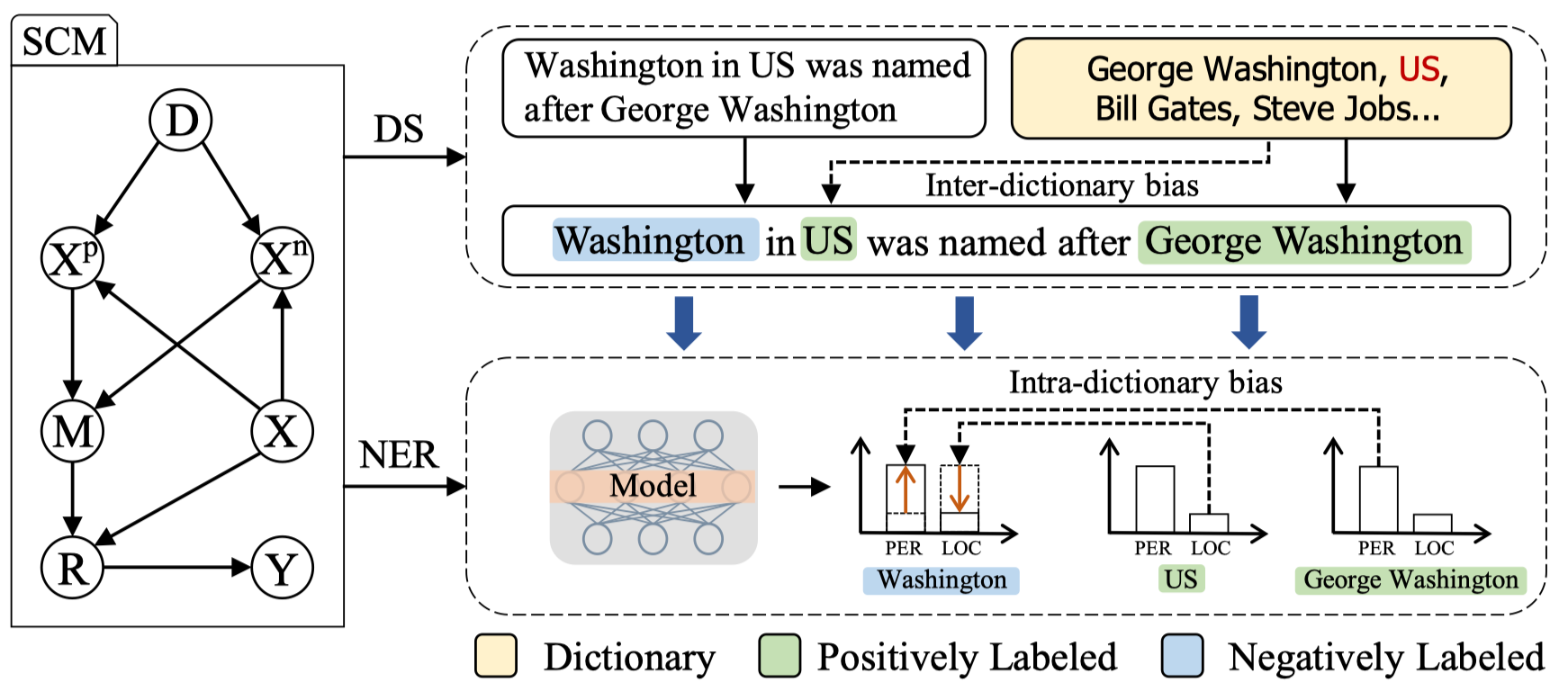
于是作者给出了DS-NER的因果图。如上图所示,其中各个符号的含义是:
-
$D$:用来远程监督的字典
-
$X$:无标注的实例,每个实例是一个(候选实体,文本),在训练阶段,$X$会被$D$自动标注
-
$X^{p}$:训练数据中的正样本实例,也就是训练数据$X$中被字典$D$标注为正样本的实体
-
$X^{n}$:训练数据中的负样本实例,也就是被$D$标注为负样本的实体
-
$M$:学习到的DS-NER模型,从标注数据中训练得到,预测新的实例
-
$R$:使用学习到的模型对数据$X$生成的表示
-
$Y$:预测的实体标签
因此,DS-NER的过程可以分为两步:远程监督和命名实体识别。
远程监督这一步会生成标注数据,然后根据如下的因果关系学习DS-NER模型:
-
$D \rightarrow X^{p} \leftarrow X$ 和 $D \rightarrow X^{n} \leftarrow X$ 表示远程监督的步骤。也就是使用字典将无标注的数据$X$分割为两个集合$X^{p}$和$X^{n}$。
-
$X^{p} \rightarrow M \leftarrow X^{n}$ 表示学习过程,也就是从分割好的数据$X^{p}$和$X^{n}$中学习DS-NER模型$M$。作者将从字典$D$中生成的两部分分别记为$X^{p}(D)$和$X^{n}(D)$。
NER这一步可以概括为:
-
$M \rightarrow R \leftarrow X$ 是表示的过程,也就是使用学习到的模型$M$编码实例$X$。
-
$R \rightarrow Y$ 表示实体识别的过程,作者将$X^{p}$和$X^{n}$识别的实体标签分别记作$Y^{p}$和$Y^{n}$。
字典内偏差的原因
给定远程监督标记数据$X^{p}$和$X^{n}$,DS-NER的学习过程是最大化如下的概率
\[P(Y^{p}=1, Y^{n}=0 \mid X^{p},X^{n},D)\]但是在上文所述的因果图中,$D$是对于$X^{p}$和$X^{n}$的混杂因子,因此,这会引入虚假关联,导致了字典内偏差:
-
当最大化$P(Y=1 \mid X^p, D)$时,通常希望NER模型依赖真实的因果路径$X^p \rightarrow Y$。然而,在SCM中存在一条后门路径$X^p \leftarrow D \rightarrow X^n \rightarrow M$,它会引入$X^p$与$Y$之间虚假关联。这个后门路径表现为$X^{n}$中的假负例,由于这些假负例有正确的实体上下文但是是字典外的名称,所以会误导模型对于实体上下文的预测欠拟合。
-
当最大化$P(Y=0 \mid X^{n},D)$时,通常希望NER模型真实的因果路径$X^{n} \rightarrow Y$。然而SCM中存在一条后门路径$X^{n} \leftarrow D \rightarrow X^{p} \rightarrow M$,他会引入$X^{n}$与$Y$之间的虚假关联。这个后门路径表现为$X^{p}$中的假正例。由于这些假正例有字典内的实体名称,但是有虚假的上下文,因此会误导模型对字典中的名称过拟合。
总的来说,字典内的偏差来源于$D$引入的后门路径,这个偏差会使得NER模型对字典内的名称过拟合,对实体的上下文欠拟合。
字典间偏差的原因
由上所述,DS-NER模型通过拟合$P(Y^{p}=1, Y^{n}=0 \mid X^{p}, X^{n}, D)$学习参数。注意到这个学习策略是以字典$D$为条件的,因此在学习$X$和$Y$之间的关系时存在$D$引入的虚假关联。理想情况下,一个鲁棒的NER模型应该拟合$P(Y \mid X)$而不是$P(Y \mid X, D)$。从SCM来看,字典$D$会显著影响模型$M$的学习,然后反过来在路径$X \rightarrow R \rightarrow Y$中产生不同的因果效应。因此,为了增强DS-NER模型的鲁棒性,模型应该学习与字典无关的实体特征。
基于因果干预的DS-NER模型去偏
对于字典内的偏差,作者提出使用后门调整的方式阻断后门路径;对于字典间的偏差,作者设计了一个因果不变正则项来捕获与字典无关的特征表示。
通过后门调整去除字典内偏差
根据上文的分析,字典内的偏差来源于后门路径$X^p \leftarrow D \rightarrow X^n \rightarrow M$和$X^{n} \leftarrow D \rightarrow X^{p} \rightarrow M$。为了消除这个偏差,作者通过同时干预$X^{p}$和$X^{n}$来阻断这两条后门路径。在执行干预后,DS-NER模型的学习便为拟合正确的因果关系$P(Y^{p}=1 \mid do(X^{p}(D)), X^{n})$和$P(Y^{n}=0 \mid do(X^{n}(D)), X^{p})$。
后门调整:为了计算干预后的分布$P\left(Y^{p}=1 \mid d o\left(X^{p}(D)\right)\right)$,作者使用后门调整计算概率
\[\begin{aligned} P_{p o s}(D) & \triangleq P\left(Y^{p}=1 \mid d o\left(X^{p}(D)\right)\right) \\ & = \sum_{i} P\left(Y^{p}=1 \mid X^{p}(D), X^{n}\left(D_{i}\right)\right) \times P\left(D_{i}\right) \end{aligned}\]$X^{n}(D_{i})$代表由DS字典$D_i$中生成的负实例。$P\left(Y^{p}=1 \mid X^{p}(D), X^{n}\left(D_{i}\right)\right)$是将$X^{p}(D)$预测为$Y=1$的概率,它可以用一个DS-NER网络来表示,即$P(Y \mid X^{p}, X^{n})=P(Y \mid X^{p}, X^{n};\theta)$。
类似地,为了阻断后门路径$X^{n} \leftarrow D \rightarrow X^{p} \rightarrow M$计算因果分布,对$X^{n}$执行后门调整
\[\begin{aligned} P_{n e g}(D) & \triangleq P\left(Y^{n} =0 \mid d o\left(X^{n}(D)\right)\right) \\ & =\sum_{i} P\left(Y^{n}=0 \mid X^{n}(D), X^{p}\left(D_{i}\right)\right) \times P\left(D_{i}\right) \end{aligned}\]由于在实际训练中只有一个字典$D$,因此无法估计上式中的$D_{i}$的概率。为此,作者从原字典$D$中采样了$K$个不同的子集字典,假设每个字典都是均匀分布,因此有$P(D_{i})=\frac{1}{K}$。
在得到$P_{pos}(D)$和$P_{neg}(D)$后,字典内的偏差可以通过$X_{p}$、$X_{n}$和$Y$之间的因果关系被消除。DS-NER模型可以最小化如下的负对数似然:
\[L_{B A}(\theta)=-\log P_{p o s}(D)-\log P_{n e g}(D)\]由于概率$P(Y\mid X_{p}, X_{n};\theta)$ 可以有不同的网络实现,因此这里的后门调整的方案可以做到model-free,也就是可以应用到各类DS-NER方法上。
通过因果不变性正则项消除字典间偏差
在执行后门调整后,$P_{pos}(D)$和$P_{neg}(D)$的优化依旧依赖于字典$D$。因此,给定不同的字典,DS-NER模型会拟合不同的因果关系,因此导致了字典间偏差。
理论上,一个鲁棒的DS-NER模型应该是与字典无关的。但是实际过程中不可能做到这样,因为无法获得$X$的真实标签$Y$。因此,为了增强模型的鲁棒性,作者提出了一个因果不变正则项,它使得模型学习有用的实体特征而不是拟合字典特有的特征。正则项的核心思想是使模型在不同的字典下保持相似的因果效应:
\[\begin{aligned} \theta_{i n v}^{*}=\arg \min _{\theta} \| P_{p o s}\left(D_{i}\right)-P_{p o s}\left(D_{j}\right) +P_{n e g}\left(D_{i}\right)-P_{n e g}\left(D_{j}\right) \| \end{aligned}\]$|| * ||$刻画了两个分布之间的距离。然而这个式子是无法直接优化的,因为$Y$是未知的。
注意到,所有的$D$对$Y$的影响都是通过路径$D \rightarrow M \rightarrow R \rightarrow Y$传播的,因此一个合理的解决方案是保持表示$R$的不变性。也就是,在给定不同字典的情况下,$X \rightarrow R$的因果效应不变,于是$X \rightarrow Y$的因果效应也就不变。因此,可以通过最小化不同字典下的$R$的表示之间的距离达到因果不变性的约束。
\[\begin{aligned} L_{C I R}(\theta ; D)=\sum_{i=1}^{K} \sum_{x \in X} \| R_{D}(x ; \theta) -R_{D^{i}}(x) \|^{2} \end{aligned}\]$R_{D}(x;\theta)$是实例$x$的表示,是通过模型$M$收到字典$D$的影响的。其他字典的生成方式和之前描述的一样。
最后,合并两个损失项,就得到了最终的去偏的DS-NER模型:
\[L=\sum_{i} L_{B A}^{i}+\lambda L_{C I R}\]实验
实验设置
作者在四个标准数据集进行实验,分别是(1)CoNLL2003(2)Twitter(3)Webpage(4)WikiGold
远程依赖的设置:(1)字符匹配String-Matching(2)知识库匹配KB-Mathcing。
Baseline模型:
-
DictMatch:在字典中直接匹配文本 -
Fully-supervised baselines:包括BiLSTM-CRF和RoBERTa-base -
Naive Distant Supervision(Naive):直接使用弱监督的数据训练有监督的模型,可以作为DS-NER模型的下界 -
Positive-Unlabeled Learning(PU-Learning):将 DS-NER 作为正的无标记学习问题。它可以获得未标记数据的无偏损失估计。 但是,它假设不存在假的正实例,因此在许多数据集中是不正确的。 -
BOND:这是一个两阶段学习算法:在第一阶段,它利用预训练的语言模型来提高NER模型的召回率和精度; 第二阶段,采用自训练的方式,进一步提升模型性能。
实验结果
主实验
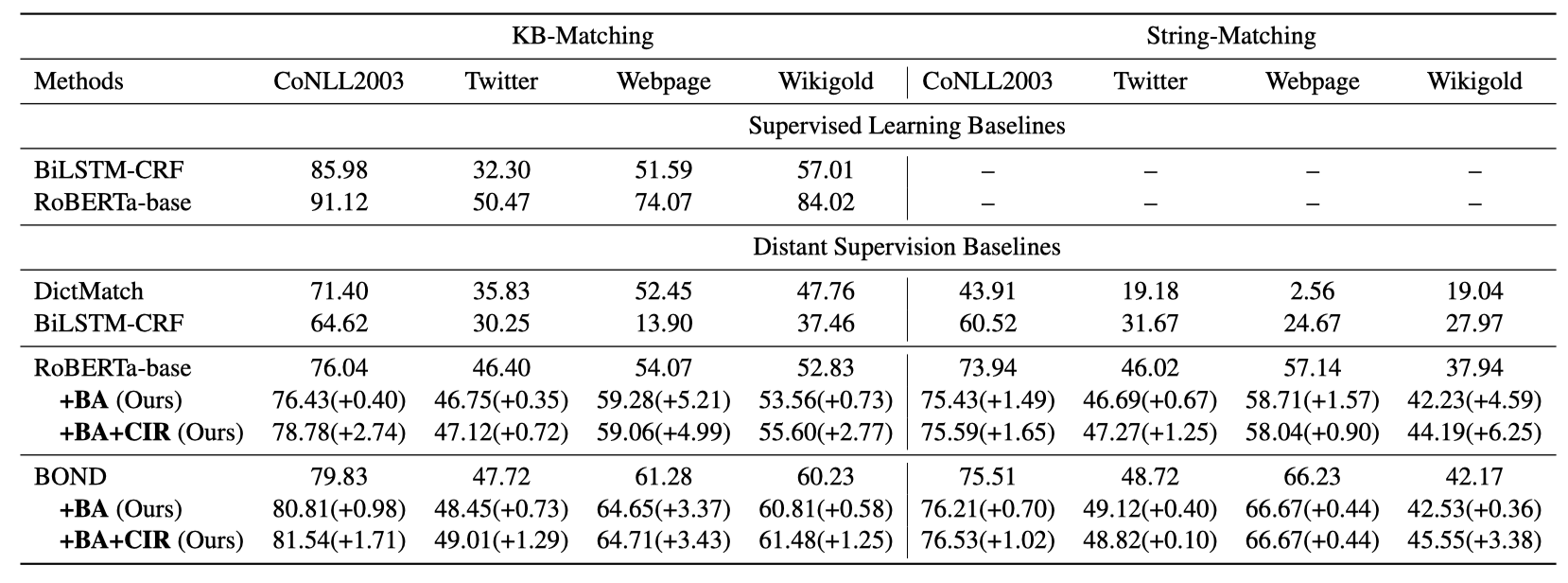
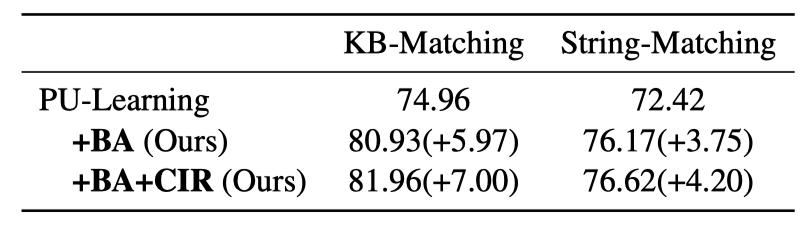
上表展示了作者在四个数据集上的实验结果(F1值)。BA和CIR分别代表后门调整和因果正则项。可以看到:
-
DS-NER模型受字典偏差的影响特别大。在没有去偏时,DS-NER只能取得和字典匹配差不多的性能。考虑到字典偏差后,PU-Learning和BOND的性能获得了极大的提升。
-
在使用因果干预之后,RoBERTa-base和BOND都取得了很好的效果提升,这证明了因果干预在DS-NER模型上的有效性。
-
后门调整和因果正则项都可以取得不错的效果提升,平均来说,在执行后门调整后,可以获得3.27%的F1值的提升;而再进一步地执行因果正则化后,可以额外地获得4.63%的F1值的提升。
鲁棒性的影响
为了验证因果正则项是否显著改善了DS-NER模型在不同字典下的的鲁棒性,作者在不同字典下进行了实验。下图是在执行去偏前后的平均预测概率。
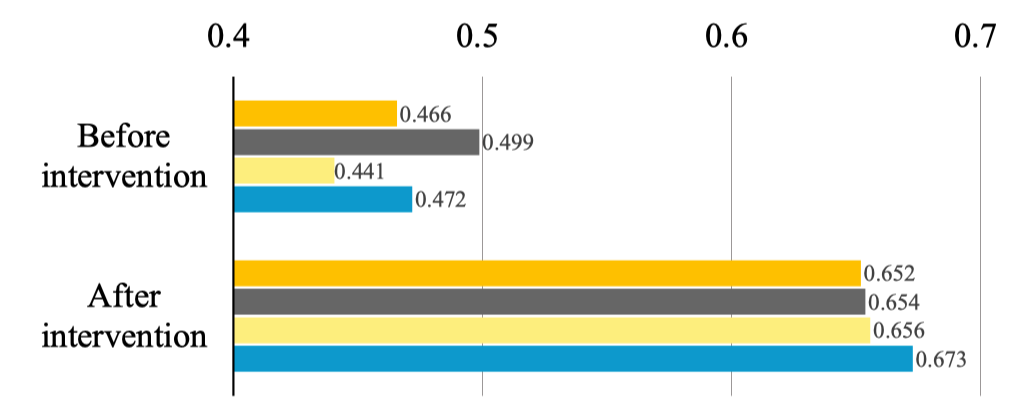
可以看出,在执行去偏后,预测概率间的差距显著减小了。这证明了去除字典间偏差后可以显著提升模型的鲁棒性。此外,可以看到真实实体的预测似然性显著提高了,这表示NER模型有更好的性能。
字典的影响
在执行因果干预时需要使用不同的字典,为了分析字典的覆盖面和数量带来的影响,作者进一步进行了一些分析实验。
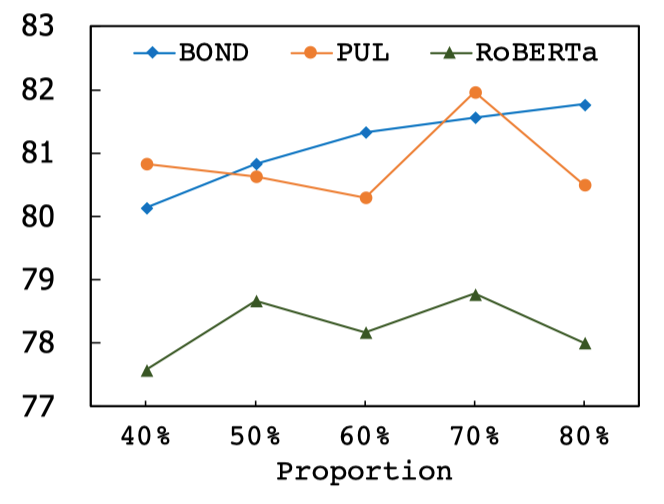
首先是不同覆盖面的字典对于效果的影响。可以看出,作者提出的去偏方法对于字典的覆盖面不敏感,从40%~80%都可以取得鲁棒的效果。
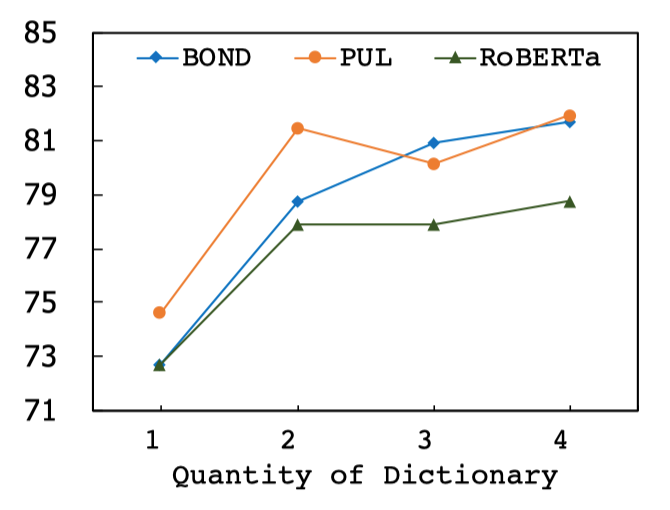
然后是字典数量的影响。可以看出,随着采样的字典数量越多,模型的效果会获得提升。这是因为更多的字典可以更精确地估计后门调整中的字典概率和因果正则项中的字典方差。
总结
这篇文章使用因果干预的方法对DS-NER模型中的字典偏差进行去偏。首先作者通过一个SCM来刻画DS-NER的过程,描述了其中的字典内偏差和字典间偏差。然后分别通过后门调整和因果不变正则项来分别消除两种偏差。最后作者通过实验证明了去偏方法的有效性和鲁棒性。