Towards Controlled and Diverse Generation of Article Comments
Introduction
自动文章评论的任务需要机器理解文章,并生成流畅的评论。这个任务有不错的应用价值,同时也有很好的研究价值。例如,不同于机器翻译或者文本摘要,自动文章评论生成可以是多样化的。对于同样一篇文章,可以从不同的角度生成不同的合适的评论。
这个任务目前仍然是比较新的,很多方面还没有研究清楚。一个很大的问题是,目前现有的文章评论生成方法都是不可控的,这就意味着评论是完全依赖文章本身的,用户无法对评论的属性进行控制。另一问题是,现有的方法都基于Seq2Seq框架,也就会面临着生成与文章无关的、没有意义的通用评论的问题。
本文中作者提出了一个可控的文章评论生成方法,它可以生成多样性的评论。作者首先构建了两个情绪数据集,一个是细粒度的,包括生气、厌恶、喜欢、开心和悲伤等情绪,第二个是粗粒度的,包括积极和消极两种情感。为了将情绪信息融入解码阶段,作者将每种情绪表示为一个向量,在解码阶段将情绪向量编码进去。同时作者采用了一个动态融合机制,在每个解码步骤中选择性地利用情感信息。此外,解码过程进一步由序列级情绪损失项引导,以增加情绪表达的强度。
为了增加多样性,作者提出了一个多层的复制机制,从输入的文章中复制词语,这是因为增强生成的评论与输入的文章之间的关联性可以抑制生成通用无意义的评论。同时作者发现,Seq2Seq框架的重复问题可以认为是缺乏句子内的多样性,因此作者采用了受限的Beam Search解码算法。
方法
作者提出的可控评论系统(Controllable Commenting System,CCS)如下图所示
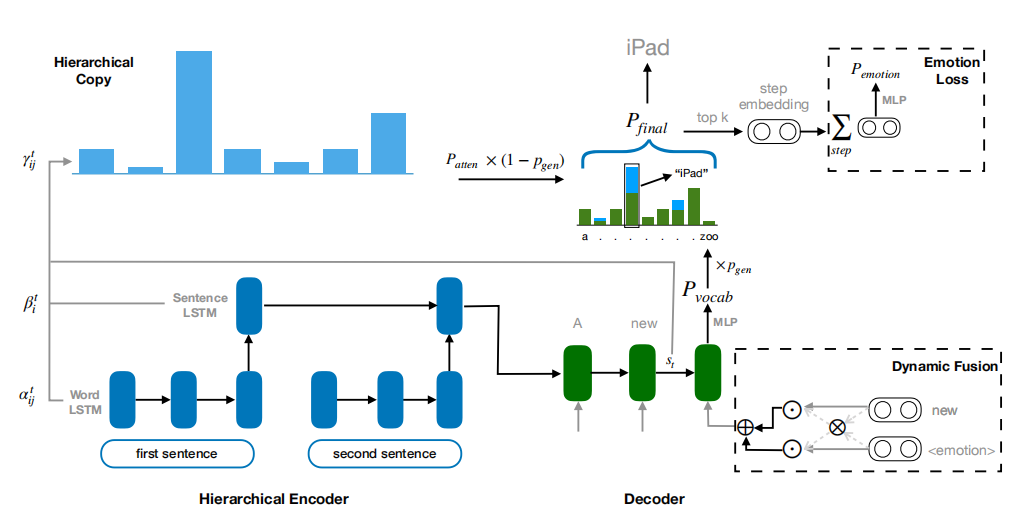
问题定义
给定一个文章 $D$ 和一个情绪类别 $\chi$,该任务的目标是生成一个合适的评论 $Y$,它可以表达出 $\chi$ 的情绪。
一般来说,$D$ 中包含 $N_D$ 个句子,每个句子包括 $T$ 个词,每个词的词向量用 $e_i$ 来表示。
层次化的Seq2Seq
作者首先在词级别编码文章 $D$,对于 $D$ 中的每个句子,使用 $\text{LSTM}_{w}^{enc}$ 来顺序读取句子,然后更新隐层状态 $h_i$:
\[h_{i}=L S T M_{w}^{e n c}\left(e_{i}, h_{i-1}\right)\]最后一层的隐层状态 $h_T$ 存储了整个句子的信息,因此可以用来表示整个句子:
\[\hat{e}=h_{T}\]得到句子表示 $(\hat{e}_{1}, \hat{e}_{2}, \ldots, \hat{e}_{N_{D}})$ 后可以在句子级别编码文章:
\[g_{i}=L S T M_{s}^{e n c}\left(\hat{e}_{i}, g_{i-1}\right)\]其中 $L S T M_{s}^{e n c}$ 是句子级别的LSTM编码器, $g_i$ 是它的隐层状态。最后一层的隐层 $g_{N_{D}}$ 聚合了所有句子的信息,可以用来初始化解码器的隐层状态。
类似地,解码器 $LSTM^{dec}$ 在每个时间步 $t$ 更新隐层状态 $s_t$
\[s_{t}=L S T M^{d e c}\left(\bar{e}_{t}, s_{t-1}\right)\]$\bar{e}_{t}$ 是上一个词的词向量,在训练的时候,使用参考句子中的词,在测试时使用上一时刻生成的词。这里同时也使用了注意力机制,如下所示
\[\begin{aligned} &m_{t, i}=\operatorname{softmax}\left(s_{t}^{T} W_{g} g_{i}\right) \\ &c_{t}=\sum_{i} m_{t, i} g_{i} \\ &a_{t}=\tanh \left(W_{a}\left[c_{t} ; s_{t}\right]+b_{a}\right) \\ &P_{\text {vocab }}=\operatorname{softmax}\left(W_{p} a_{t}\right) \end{aligned}\]